Home
Pricing
Login
Login
Real Time Inference
Model deployment platform powered by
Hathora Cloud
Book a demo
Book a demo
Who is it for?
Deploying custom models
Inference speed matters
High inference volume
Hathora in production
2.2s
container boot time
30k+
cores under management
32ms
avg edge latency
Built by an experienced team, backed by top investors, and used by millions.
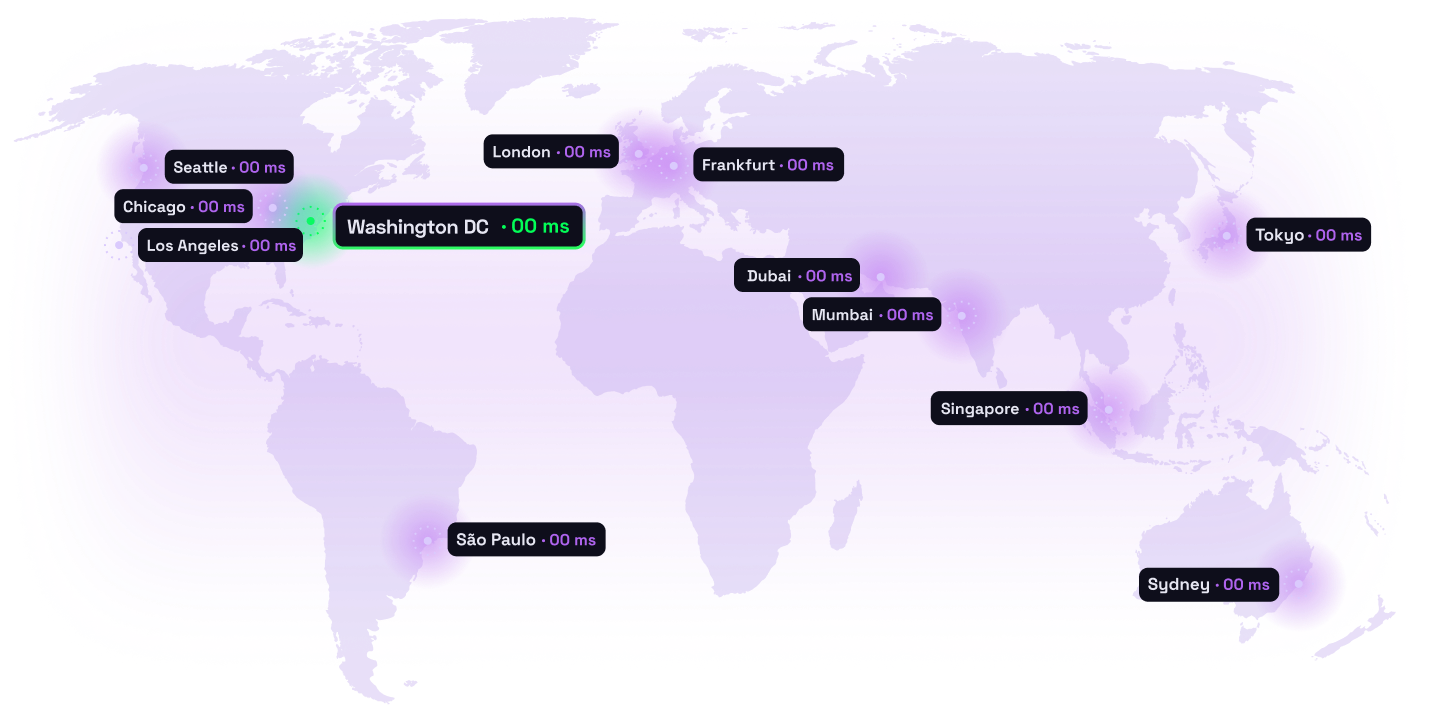
Performance
Latency-optimized delivery via multi-region deployment
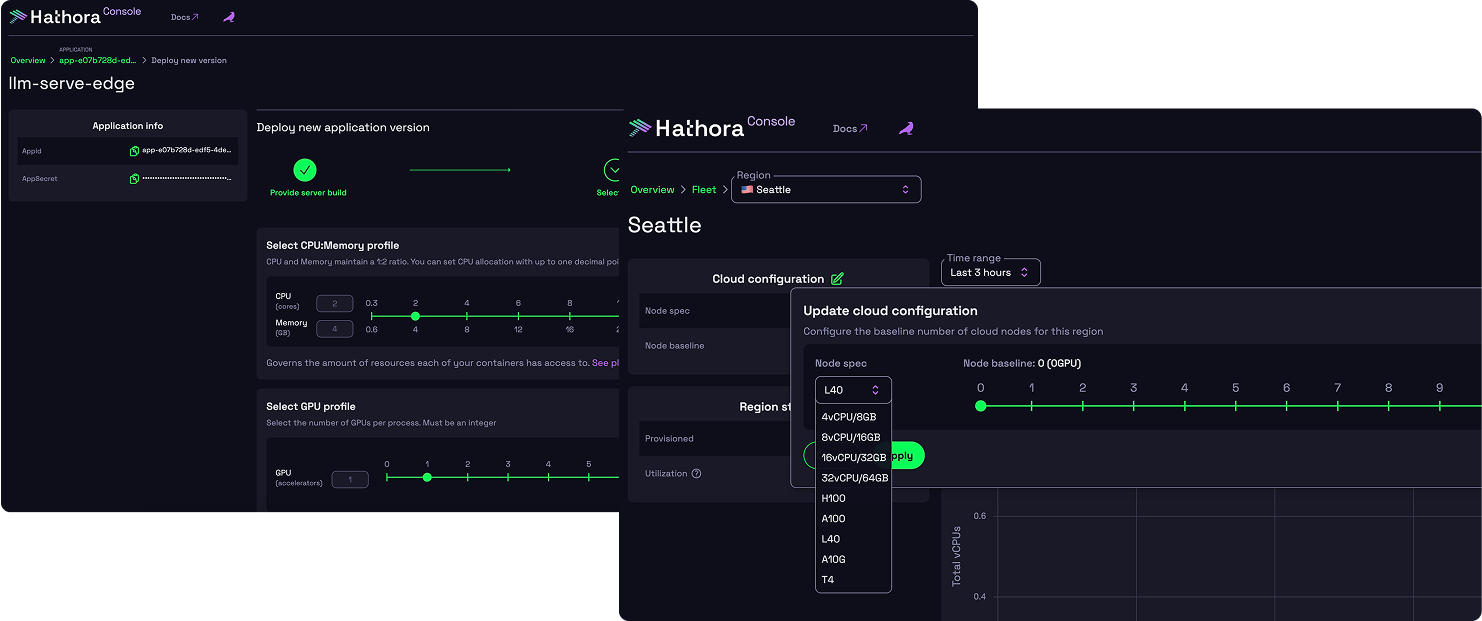
Custom Deployments
Hathora Cloud aggregates compute to enable using GPU and CPU chips from anywhere
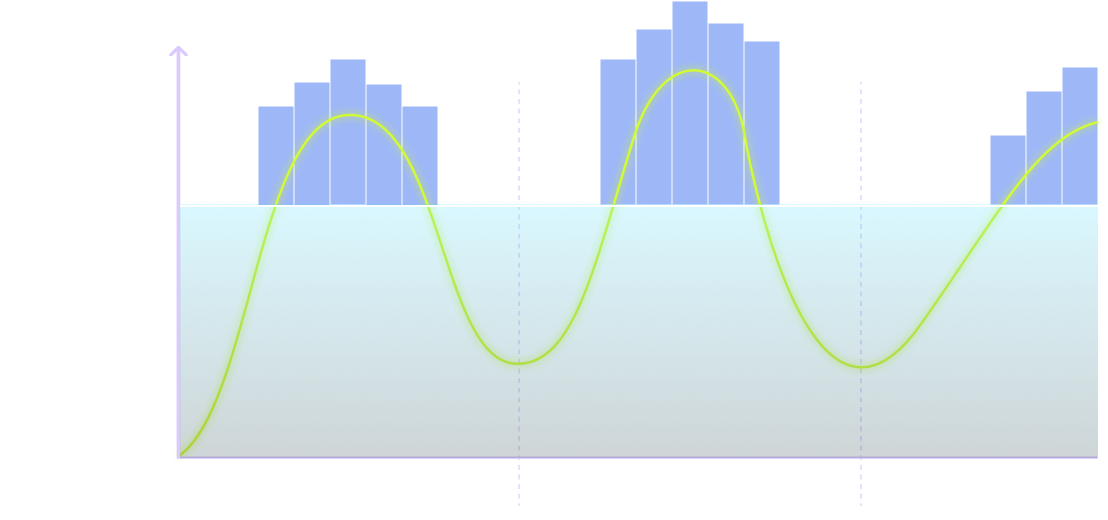
Cost Efficiency
Blend cost-effective bare metal with cloud elasticity, scaling effortlessly to match demand while not breaking the bank
Use cases
Voice Models
Make voice feel as real as possible by serving your models to your users with ultra low latency
Auto-complete
Minimize wasted inference cycles by getting an answer to your users fast
Interactive Robotics
Bring life-like reaction time to the home assistant that you build for your customers